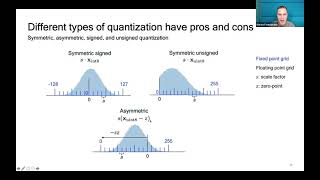
tinyML Talks: A Practical Guide to Neural Network Quantization Share: Download MP3 Similar Tracks Quantization vs Pruning vs Distillation: Optimizing NNs for Inference Efficient NLP But what is a neural network? | Deep learning chapter 1 3Blue1Brown tinyML Talks: Empowering the Edge: Practical Applications of Embedded Machine Learning on MCUs EDGE AI FOUNDATION tinyML Talks Lukas Geiger: Binarized Neural Networks on microcontrollers EDGE AI FOUNDATION Model Quantization for Edge Devices with AIMET The TWIML AI Podcast with Sam Charrington Illustrated Guide to Transformers Neural Network: A step by step explanation The AI Hacker tinyML Talks South Africa: An Introduction to TinyML for all backgrounds with hands on intro... EDGE AI FOUNDATION Backpropagation Details Pt. 1: Optimizing 3 parameters simultaneously. StatQuest with Josh Starmer But what is a convolution? 3Blue1Brown A Hackers' Guide to Language Models Jeremy Howard Pulse-Doppler Radar | Understanding Radar Principles MATLAB Physics Informed Neural Networks (PINNs) [Physics Informed Machine Learning] Steve Brunton Quantization in Deep Learning (LLMs) AI Bites Quantization in deep learning | Deep Learning Tutorial 49 (Tensorflow, Keras & Python) codebasics Low-rank Adaption of Large Language Models: Explaining the Key Concepts Behind LoRA Chris Alexiuk Pruning Deep Learning Models for Success in Production Neural Magic Transformer Neural Networks, ChatGPT's foundation, Clearly Explained!!! StatQuest with Josh Starmer Which Quantization Method is Right for You? (GPTQ vs. GGUF vs. AWQ) Maarten Grootendorst Understanding GANs (Generative Adversarial Networks) | Deep Learning DeepBean Neural Networks from Scratch - P.1 Intro and Neuron Code sentdex